

Apprendre un langage demande de se familiariser avec un interface, un outil de travail convivial, flexible et sympathique. J’essaie donc Thonny, disponible sur Linux (sur le Raspberry Pi 400 initialement). C’est un langage INTERPRÉTÉ, et non compilé. C’est un langage compréhensible en environnement Mac OS, Linux/Unix ou Windows. La même expérience pourrait se faire en mode terminal, lorsque Python est installé sur l’ordinateur.
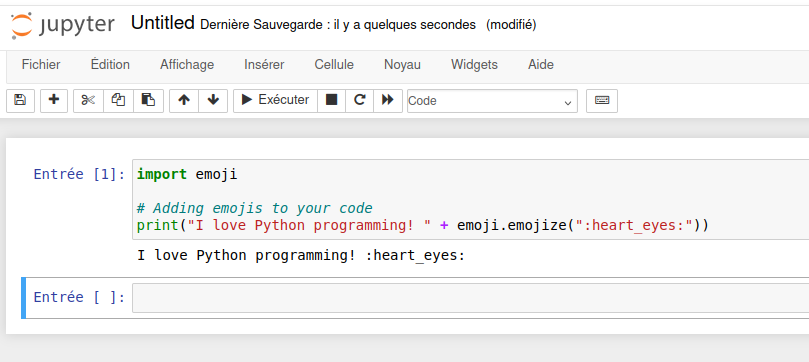
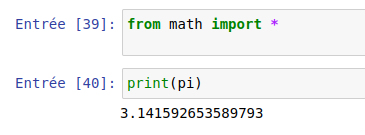
Juste une première commande rends l’expérience concluante:
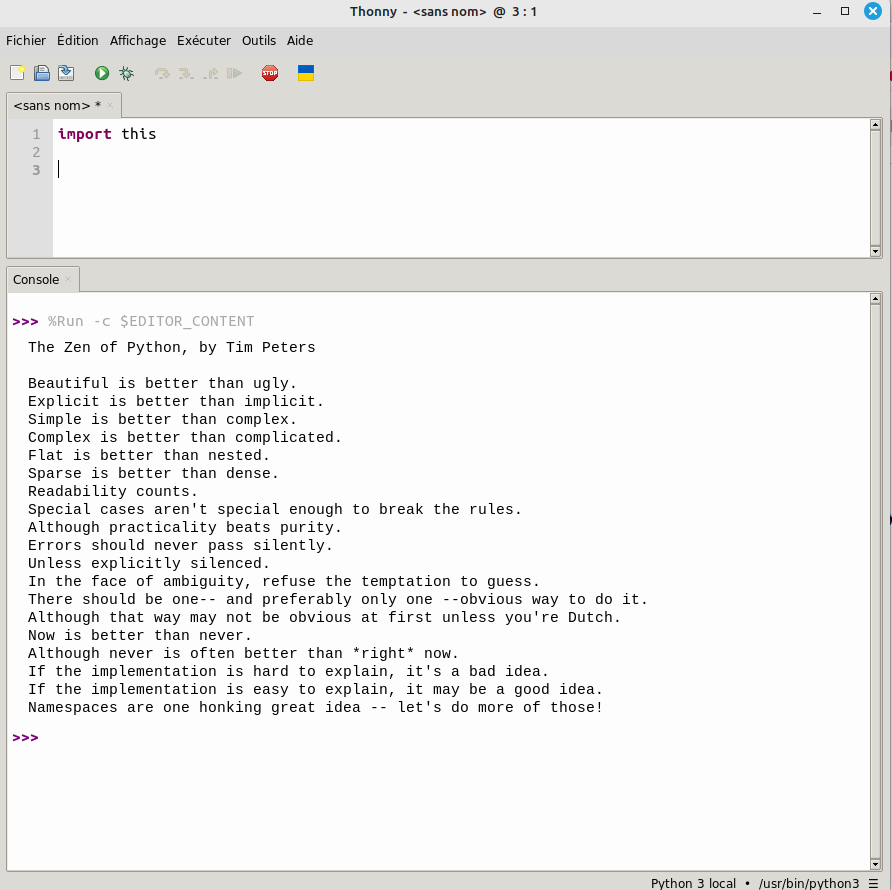
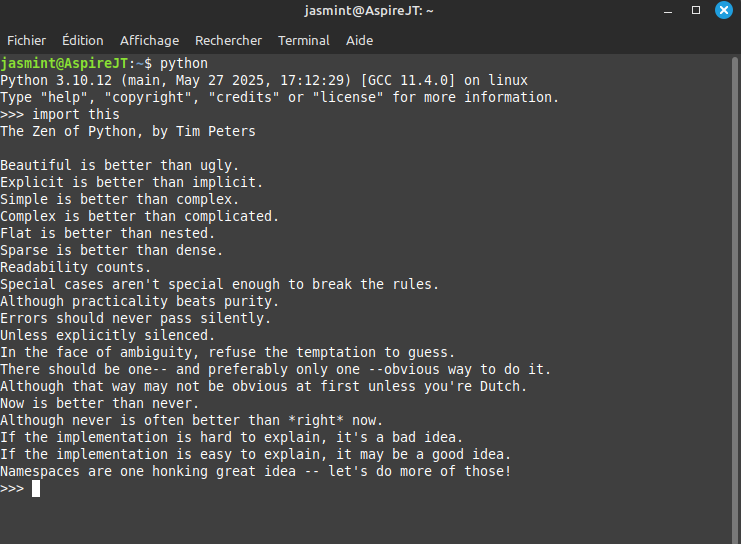
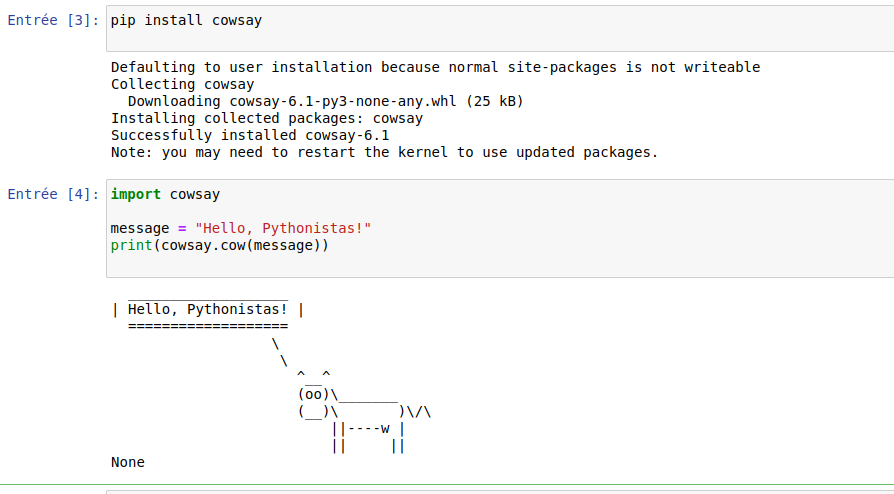
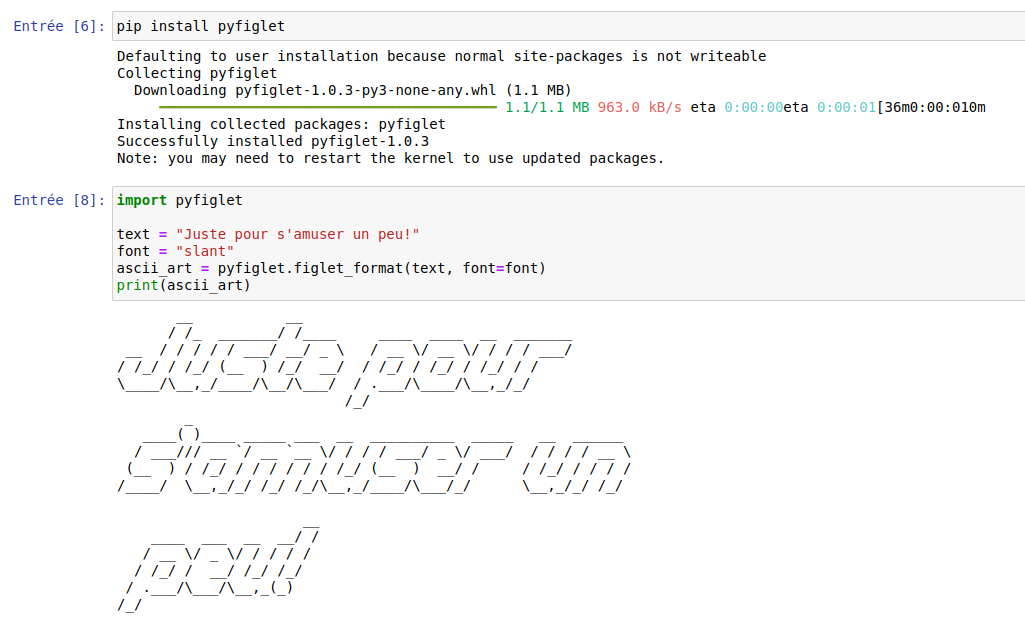
C’est comme essayer différentes librairies, juste pour le fun:
import antigravity
Après quelques essais avec Thonny, on atteind ses limites. C’est bien pour s’initier à la programmation… de base.
De programmer dans un fichier texte notre code, et de le tester en mode terminal est un bon moyen pour apprendre aussi.
On retrouve sur certains tutoriels des utilisateurs en environnement Windows qui utilisent une VirtualBox, un émulateur d’environnement Debian Linux.
Parfois, on peut avoir besoin de faire exécuter un script en passant des arguments (paramètres) à notre code:
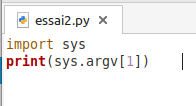

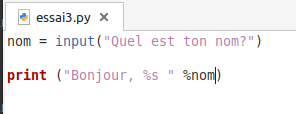
Parfois, il faut faire des conversions de conventions d’écritures entre les versions de Python (nous en sommes è la version 3 actuellement).

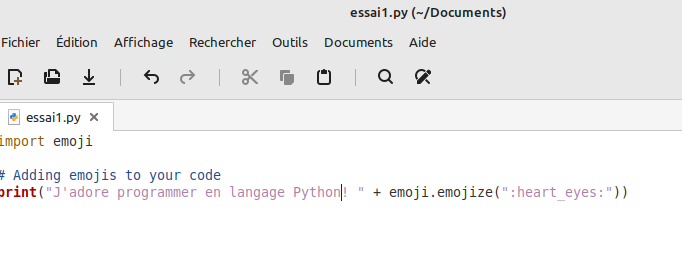
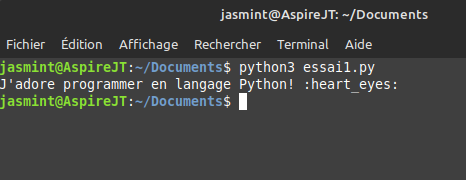
Mais le meilleur outil vraiment performant demeure avec l’interface de Jupyter NoteBooks, ou bien avec Visual Studio Code!!!
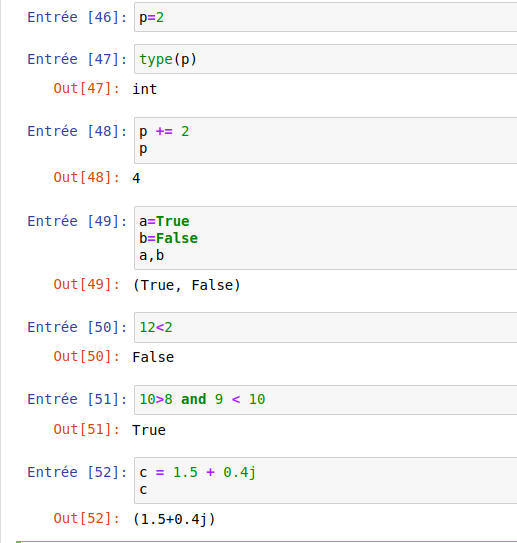
Exercice de réchauffement:


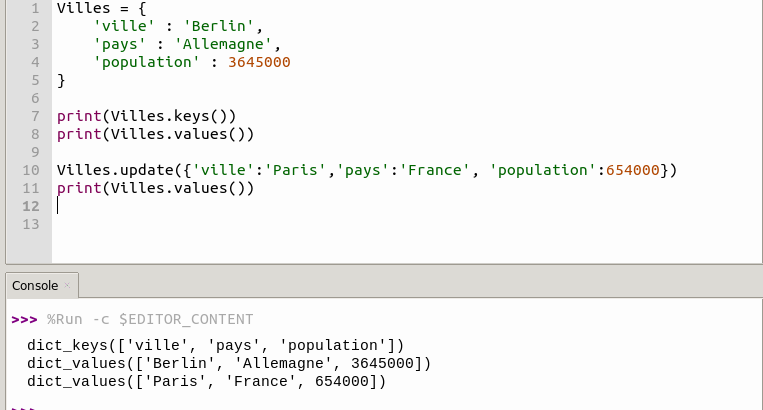
| En Python, un object (objet) et un identifier (identifiant) sont deux concepts liés mais distincts : 1. Object (Objet) Un objet est une instance d’une classe, représentant une structure de données avec : Un type (par exemple, int, str, list, ou une classe personnalisée).Une valeur (le contenu de l’objet). Un identifiant unique (adresse mémoire, accessible via id(obj)).Exemple : x = 42 # 42 est un objet de type `int`2. Identifier (Identifiant) Un identifiant est un nom utilisé pour faire référence à un objet (variable, fonction, classe, etc.). Il agit comme une étiquette (ou un pointeur) vers l’objet en mémoire. Exemple : y = "hello" # `y` est un identifiant qui référence l'objet `"hello"`Différence claire : L’objet est la donnée réelle en mémoire. L’identifiant est le nom que vous utilisez pour accéder à cet objet. Exemple illustratif : a = [1, 2, 3] # `a` est un identifiant référençant un objet `list` b = a # `b` est un autre identifiant pour le même objet print(id(a) == id(b)) # True (même objet en mémoire)Cas particulier : Mutabilité Pour les objets mutables (comme les listes), modifier l’objet via un identifiant affecte toutes les références : a.append(4) print(b) # [1, 2, 3, 4] (car `a` et `b` pointent vers le même objet)Résumé : Concept Description Exemple Object Donnée en mémoire avec un type et un ID. 42, "hello", [1, 2]Identifier Nom utilisé pour référencer un objet. x, ma_liste, funcEn résumé, un identifiant est comme une étiquette, tandis qu’un objet est la « chose » à laquelle l’étiquette est collée. |

En Python, un objet mutable est un objet dont l’état (la valeur) peut être modifié après sa création. En d’autres termes, on peut changer les valeurs contenues dans un objet mutable sans créer un nouvel objet. Les listes, les dictionnaires et les ensembles sont des exemples de types de données mutables.
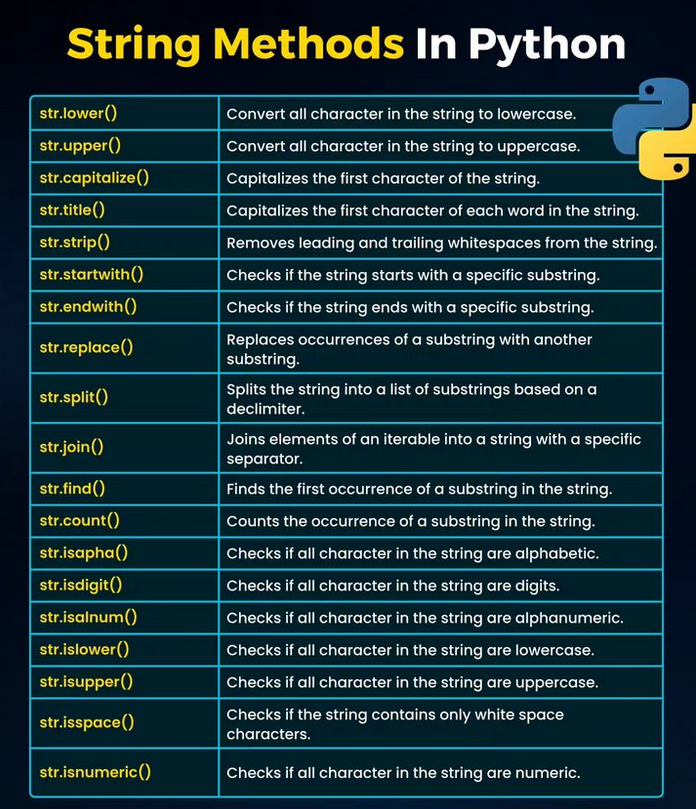


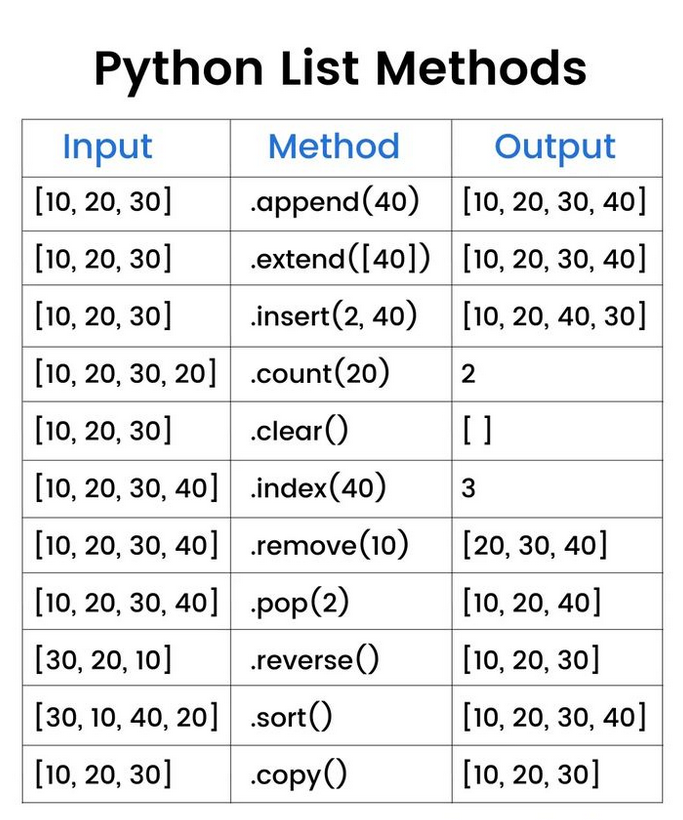

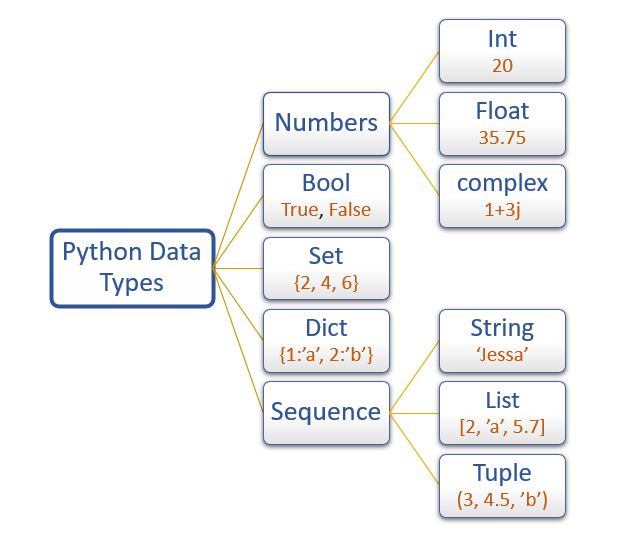
En Python, tuples, sets, lists et dictionaries sont des structures de données différentes, chacune avec ses propres caractéristiques et cas d’utilisation. Voici leurs différences :
1. List (list)
- Mutable (modifiable après création).
- Ordonnée (les éléments ont un index).
- Permet les doublons.
- Délimitée par des crochets
[]. - Utilisée pour stocker une collection ordonnée d’éléments.
Exemple :
ma_liste = [1, 2, 3, 2] # Valide
ma_liste[0] = 10 # Modifiable
2. Tuple (tuple)
- Immutable (non modifiable après création).
- Ordonné (accès par index).
- Permet les doublons.
- Délimité par des parenthèses
(). - Utilisé pour des données fixes (coordonnées, configurations, etc.).
Exemple :
mon_tuple = (1, 2, 3, 2) # Valide
mon_tuple[0] = 10 # Erreur (immutable)
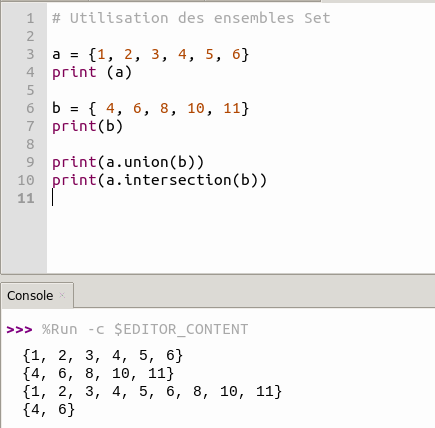
3. Set (set)
- Mutable (modifiable, mais ses éléments doivent être immuables).
- Non ordonné (pas d’index).
- Pas de doublons (stocke des éléments uniques).
- Délimité par des accolades
{}ouset(). - Optimisé pour les tests d’appartenance (
in) et les opérations ensemblistes (union, intersection).
Exemple :
mon_set = {1, 2, 3, 2} # Devient {1, 2, 3}
mon_set.add(4) # Valide
4. Dictionnaire (dict)
- Mutable (modifiable).
- Non ordonné (avant Python 3.7, ordonné ensuite).
- Stocke des paires clé-valeur (
key: value). - Clés uniques (pas de doublons), valeurs peuvent être dupliquées.
- Délimité par des accolades
{}avecclé: valeur.
Exemple :
mon_dict = {"nom": "Alice", "âge": 25}
mon_dict["ville"] = "Paris" # Ajout/modification possible
Résumé Comparatif
| Caractéristique | List ([]) | Tuple (()) | Set ({}) | Dict ({key: value}) |
|---|---|---|---|---|
| Mutable | Oui | Non | Oui | Oui |
| Ordonné | Oui | Oui | Non | Oui (depuis Python 3.7) |
| Doublons | Oui | Oui | Non | Clés uniques |
| Accès | Par index | Par index | Boucle/in | Par clé |
| Cas d’usage | Collection modifiable | Données fixes | Éléments uniques | Association clé-valeur |
Quand utiliser chaque structure ?
- Liste : Quand on a besoin d’une collection ordonnée et modifiable.
- Tuple : Pour des données immuables (ex : clés de dictionnaire, retour multiple de fonctions).
- Set : Pour éliminer des doublons ou faire des opérations ensemblistes.
- Dictionnaire : Pour représenter des données structurées (ex : JSON, bases de données).
Le Zen de Python




A Python Style Guide
- Keep your code tidy and well-readable.
- Provide comments in your code.
- Group your code into blocks, separated by blank lines.
- Use indentation wisely.
- Pick meaningful names for your identifiers.

Listes

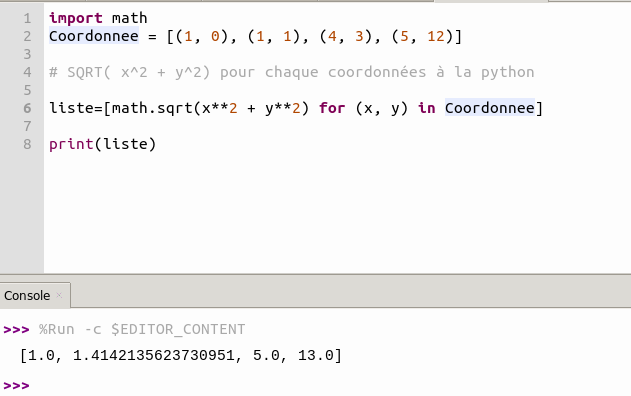
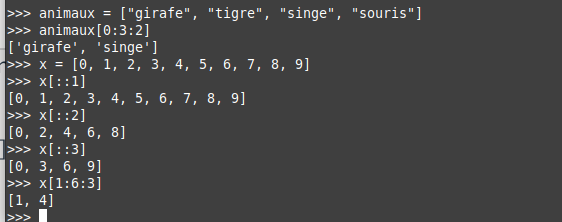
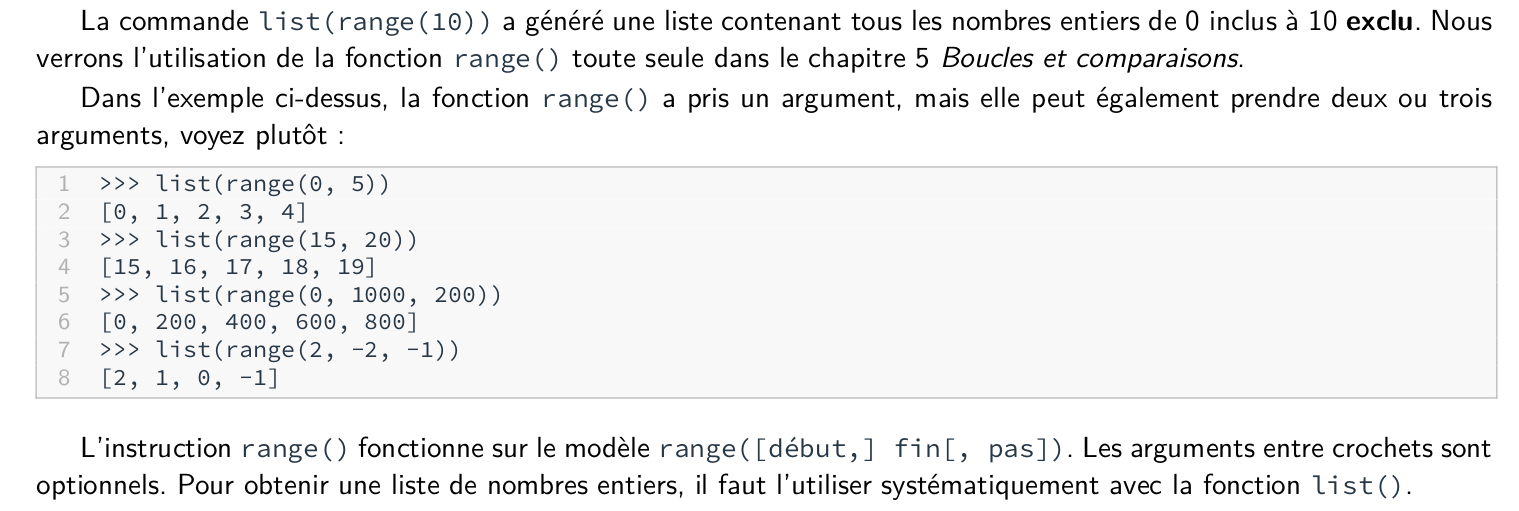
On peut aussi préciser le pas en ajoutant un symbole deux-points supplémentaire et en indiquant le pas par un entier :
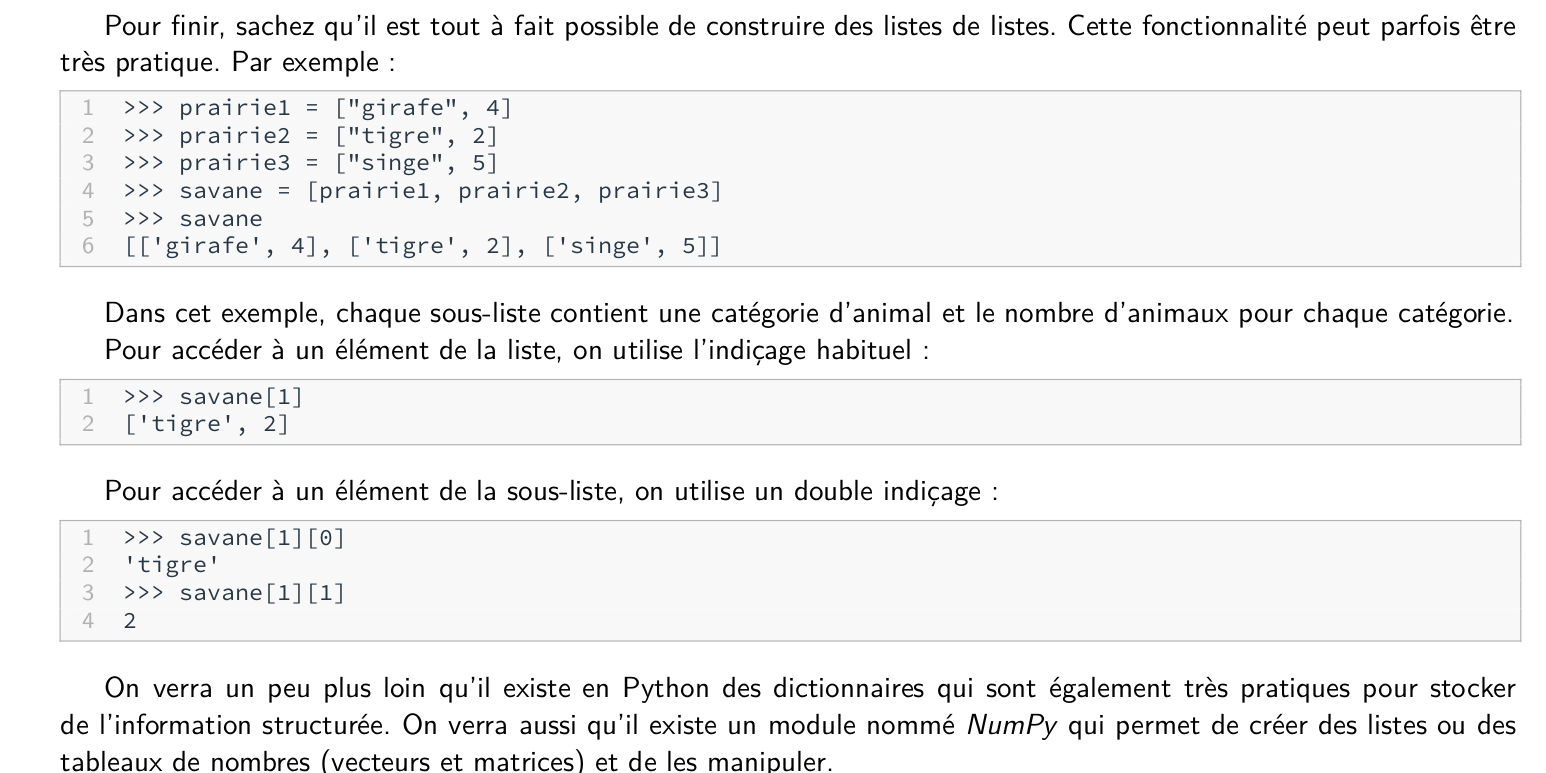
Liste de listes
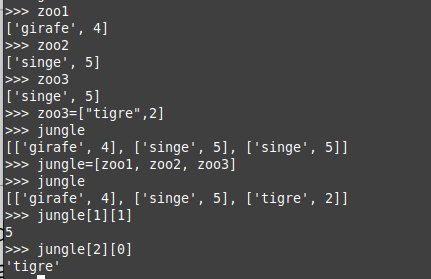
Créez quatre listes hiver, printemps, ete et automne contenant les mois correspondants à ces saisons. Créez ensuite une liste saisons contenant les listes hiver, printemps, ete et automne. Prévoyez ce que renvoient les instructions suivantes, puis vérifiez-le dans l’interpréteur :
- saisons[2]
- saisons[1][0]
- saisons[1:2]
- saisons[:][1]. Comment expliquez-vous ce dernier résultat ?
Définition
hiver = ["décembre", "janvier", "février"]
printemps = ["mars", "avril", "mai"]
été = ["juin", "juillet", "août"]
automne = ["septembre", "octobre", "novembre"]
saisons = [hiver, printemps, été, automne]
Résultats attendus / observés
saisons[2]→['juin', 'juillet', 'août']
Retourne la troisième sous-liste (été).saisons[1][0]→'mars'
On prend la deuxième sous-liste (printemps), puis son premier élément.saisons[1:2]→[['mars', 'avril', 'mai']]
Le slicing retourne une liste contenant les éléments de l’indice 1 à 2 (exclu) : ici une liste d’un seul élément, qui est la sous-listeprintemps.saisons[:][1]→['mars', 'avril', 'mai']saisons[:]fait une copie superficielle de la listesaisons(même références aux sous-listes), puis[1]en extrait directement la sous-listeprintemps.
Pourquoi saisons[:][1] donne le même résultat que saisons[1] et pas une liste imbriquée ?
saisons[:]crée une copie superficielle de la liste extérieure ; c’est une nouvelle liste dont les éléments sont les mêmes objets (les sous-listes).- Ensuite,
[1]indexe cette copie pour en extraire l’élément d’indice 1, donc la sous-listeprintempselle-même. - En revanche,
saisons[1:2]fait un slicing qui retourne une liste contenant cet élément, d’où la différence de niveau d’imbrication. - On peut vérifier que
saisons[1] is saisons[:][1]estTrue, donc ce n’est pas une nouvelle sous-liste, c’est la même référence.
Résumé
saisons[2]→ sous-listeété.saisons[1][0]→ chaîne'mars'.saisons[1:2]→ liste contenant la sous-listeprintemps.saisons[:][1]→ la sous-listeprintempsdirectement (commesaisons[1]), parce que on a copié l’extérieur puis indexé.
