

Première approche:
- Ils utilisent Jupyter.
- Nombreux exemples de codes en Python de disponibles.
- Le titre est clair: Niveau Undergraduate Student.
- Présentation des outils essentiels à la Data Science
- Informations détaillées et précises, diversifiées pour toute manipulation nécessaire! Un must!!!
- Exemple… explication simplifiée… exemple… info complémentaire! Génial! Facile à tester!!!
- Autant avec le volume de référence qu’avec les fichiers fournis!
- Quand l’environnement est fiable, stable, flexible dans ses paramètres (Linux), quand l’interface est compréhensible, simplifié, fonctionnel, clair et précis (Jupyter), c’est un charme à tester, assez pour transférer ses connaissances avec un autre modèle!
Descriptive Statistics
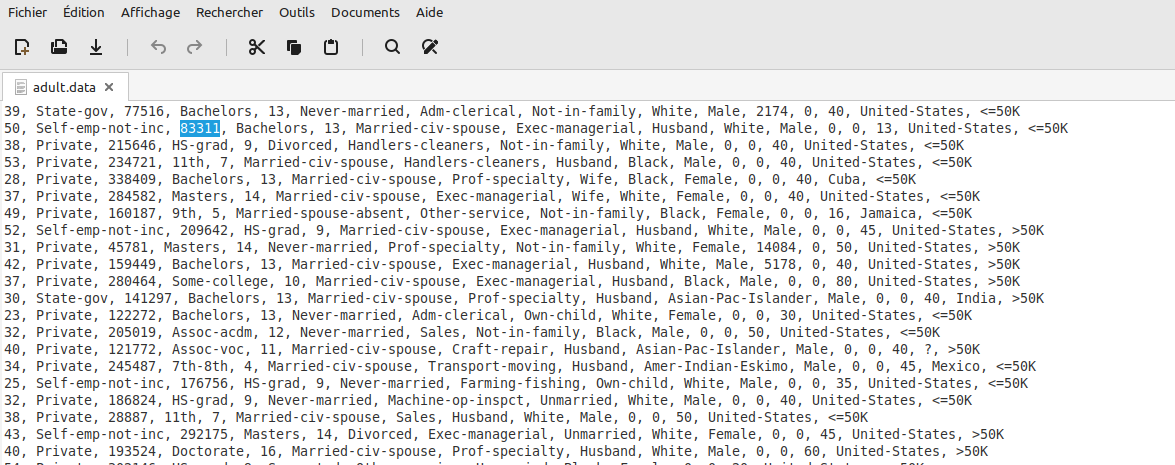
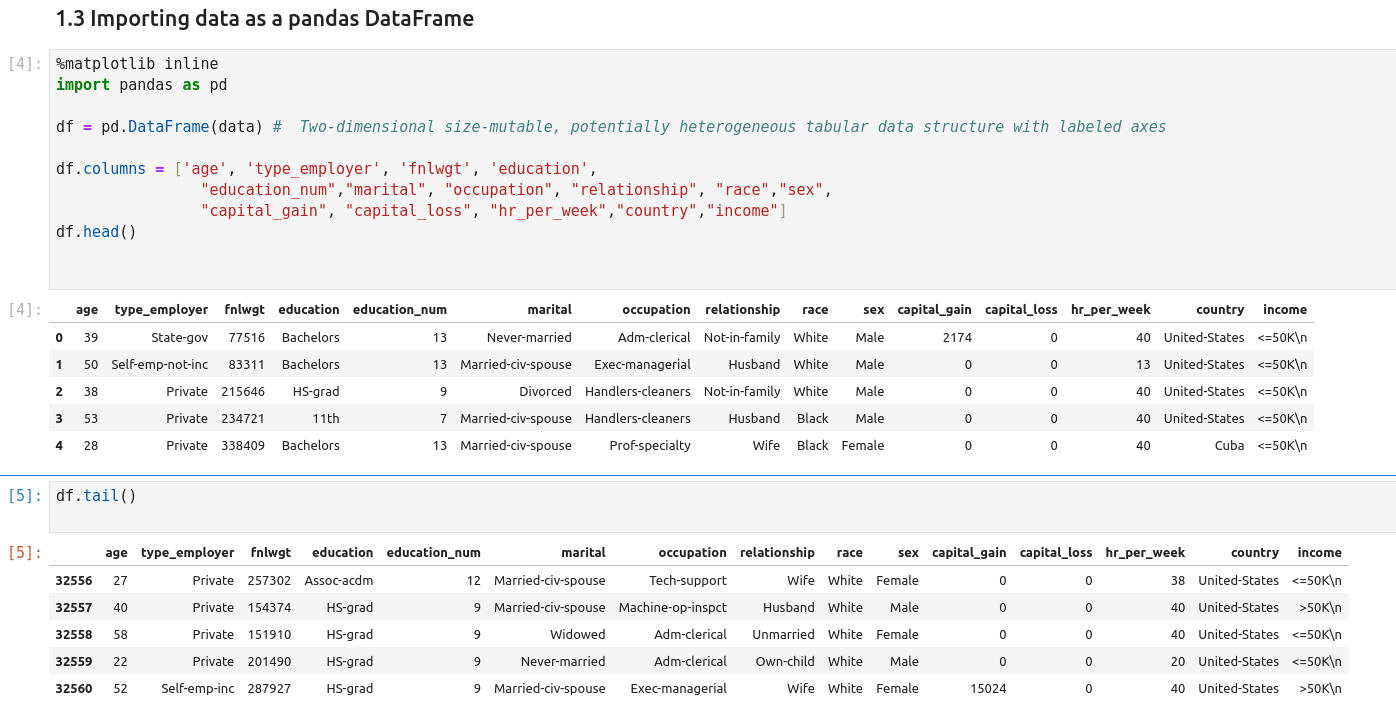
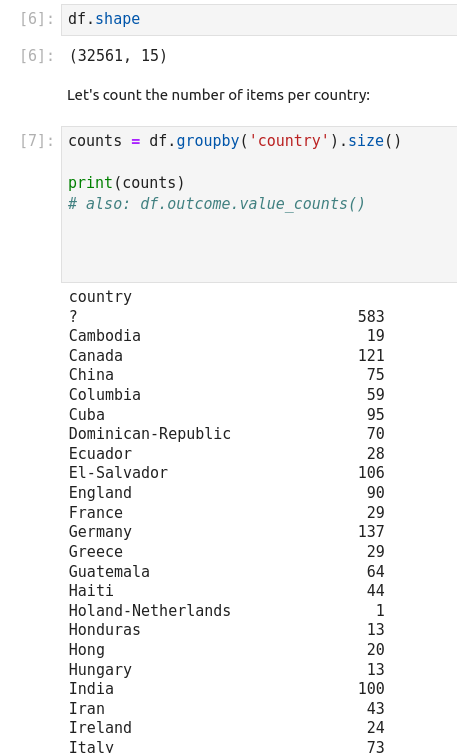
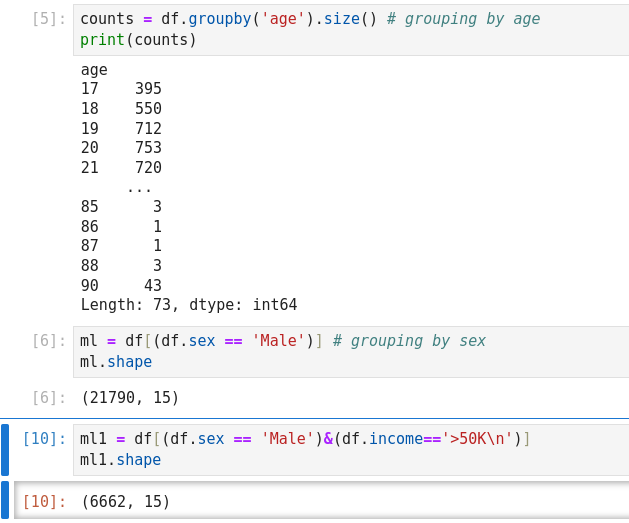
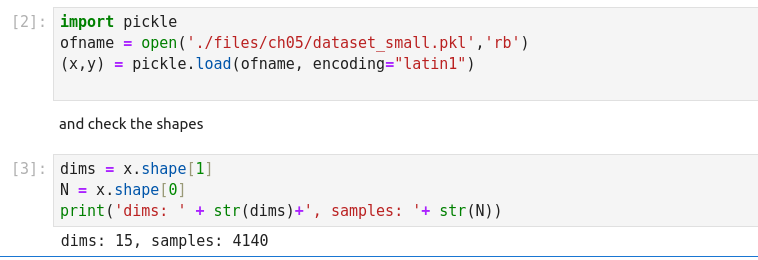
Getting Data


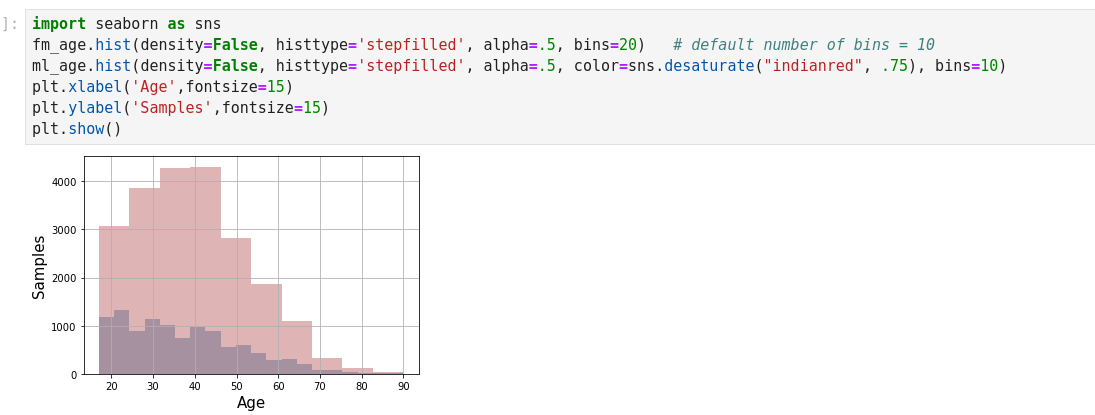
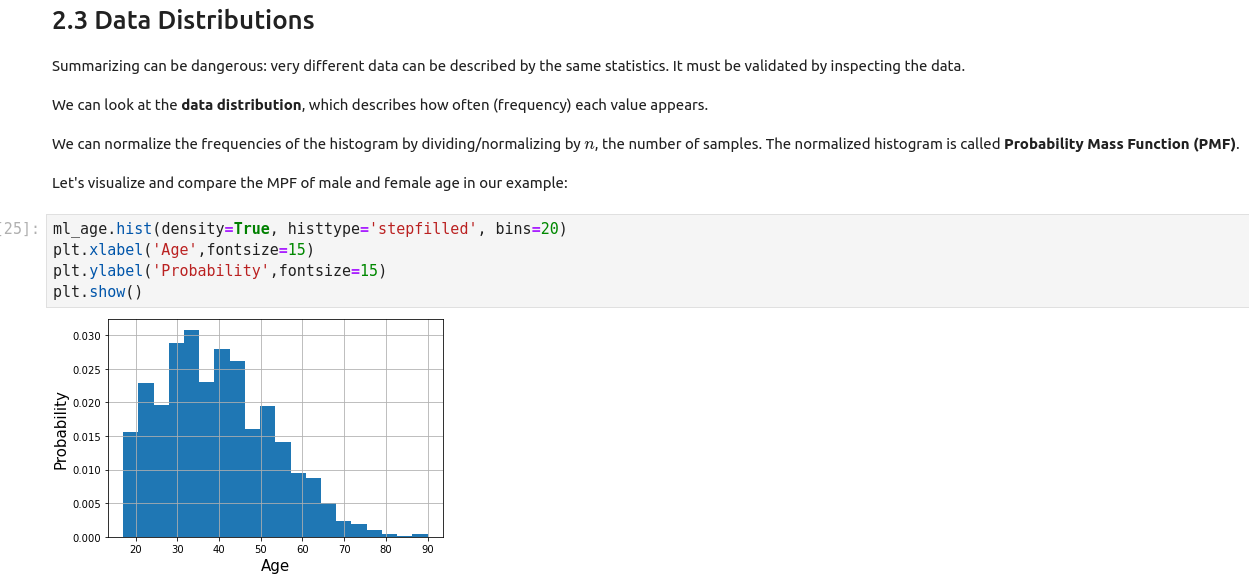
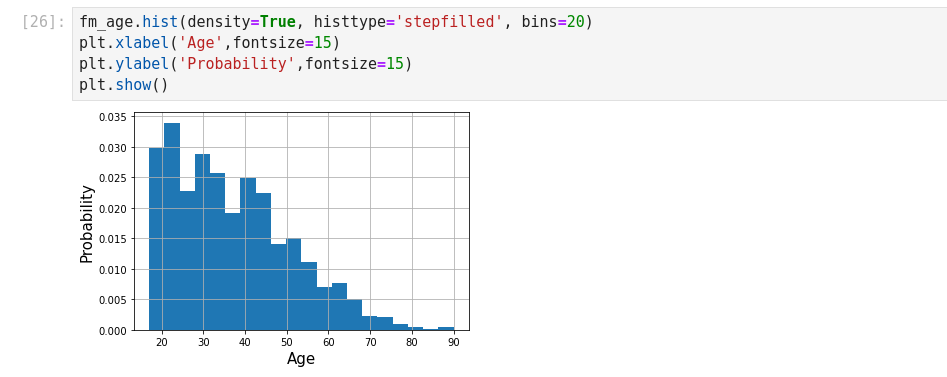
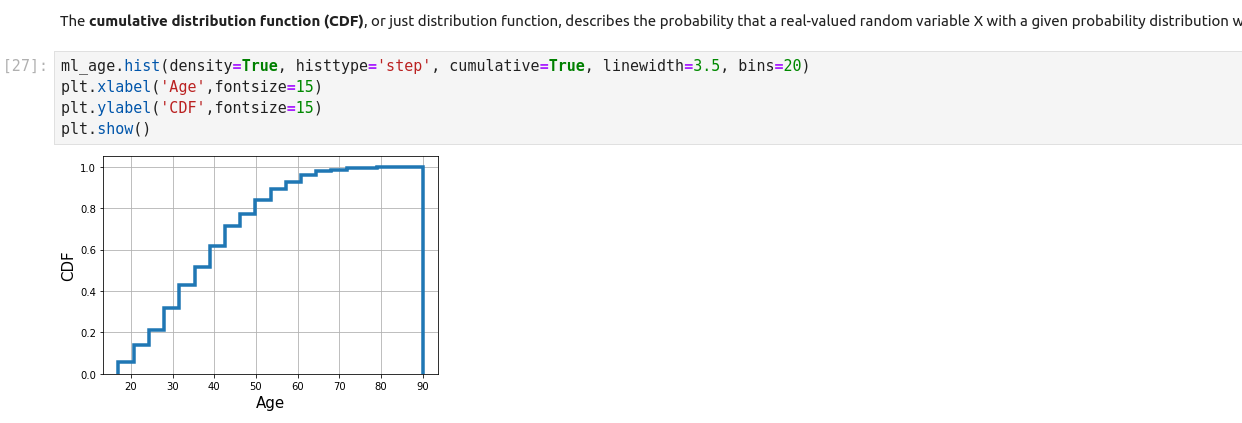

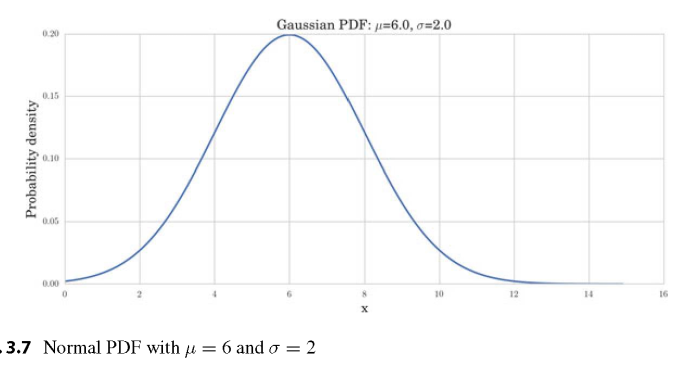
Normal Distribution
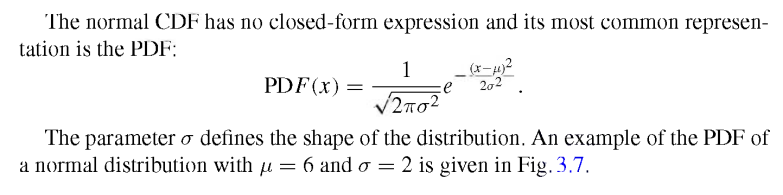
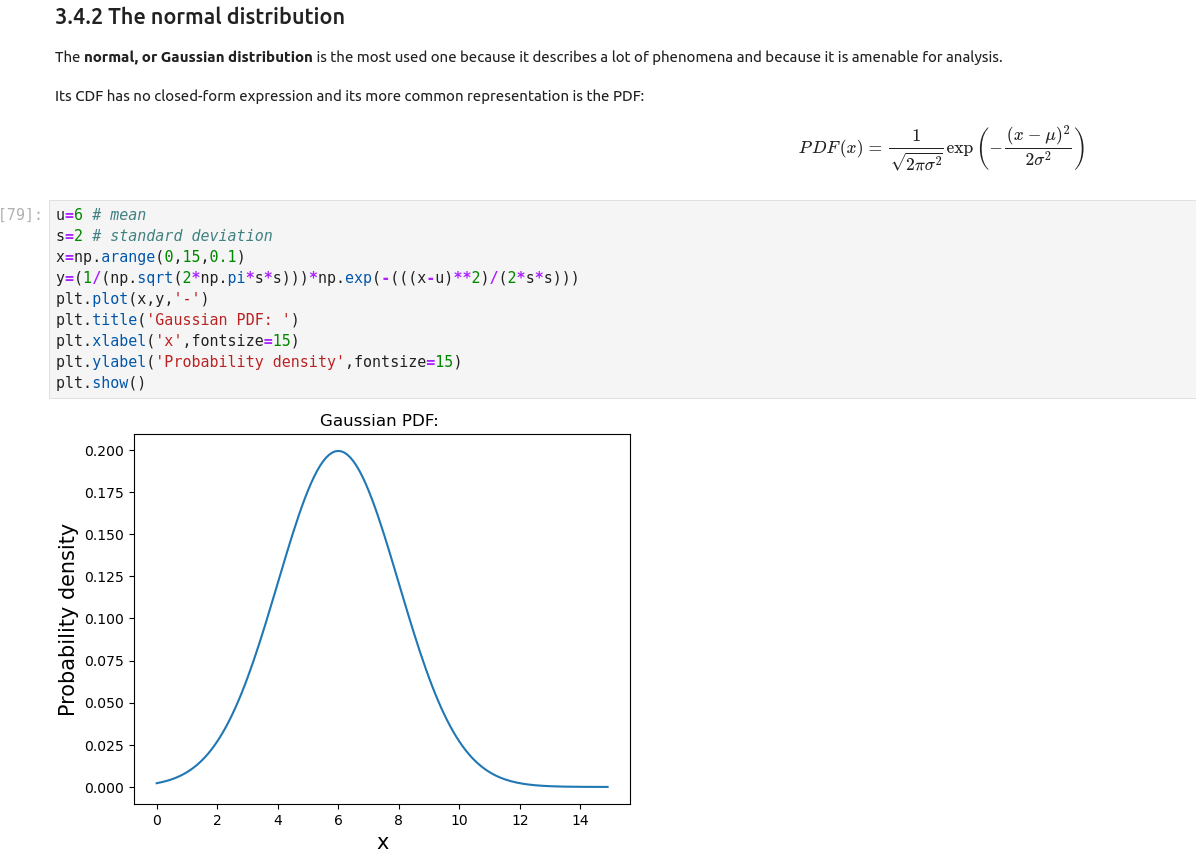
Statistical Inference


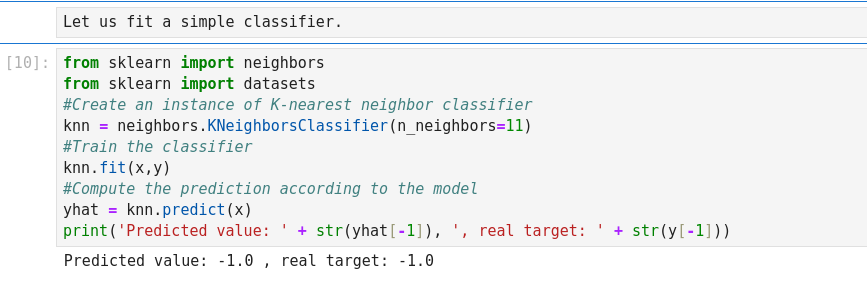
Supervised Learning




Pickle is a new format from Apple that is designed to address the shortcomings of JSON and YAML. Pickle is a programming language that can be used to define configuration files. This means that Pickle files can be more expressive than JSON or YAML, and can also include logic and validation.
- 40% of all PKL files start with the bytes 80 03, which are crucial for this file format. These are binary files, so they do not contain words or text. The files are 700 bytes to 23 MB in size, with a median of 270 KB. It is a modern file type. The following keywords are characteristic: core and csklearn. Some examples of file names are model.pkl. Such files sometimes refer to data, train, dataset, classes, words, features, prediction and classifier.
- 35% of all PKL files use the same file format, which can be identified by the letters « 80 04 95 » at the beginning. They consist of illegible, cryptic characters. The file size is in the range of 570 bytes to 34 MB. Several words can almost always be found in the files, e.g. core and numpy. These files are attributed to result, dict, cookies, random, stylegan and list.
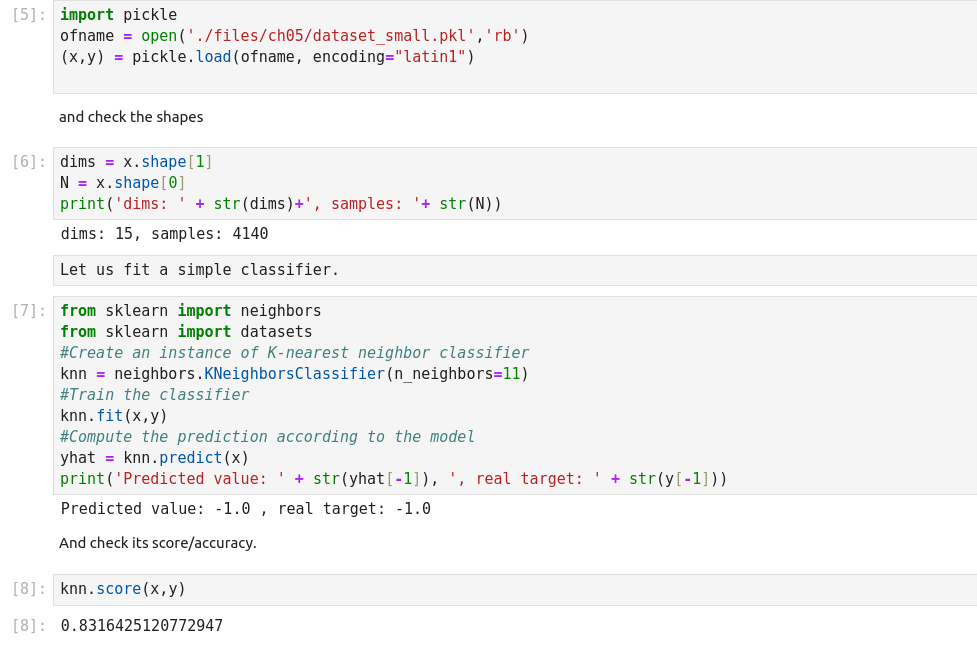
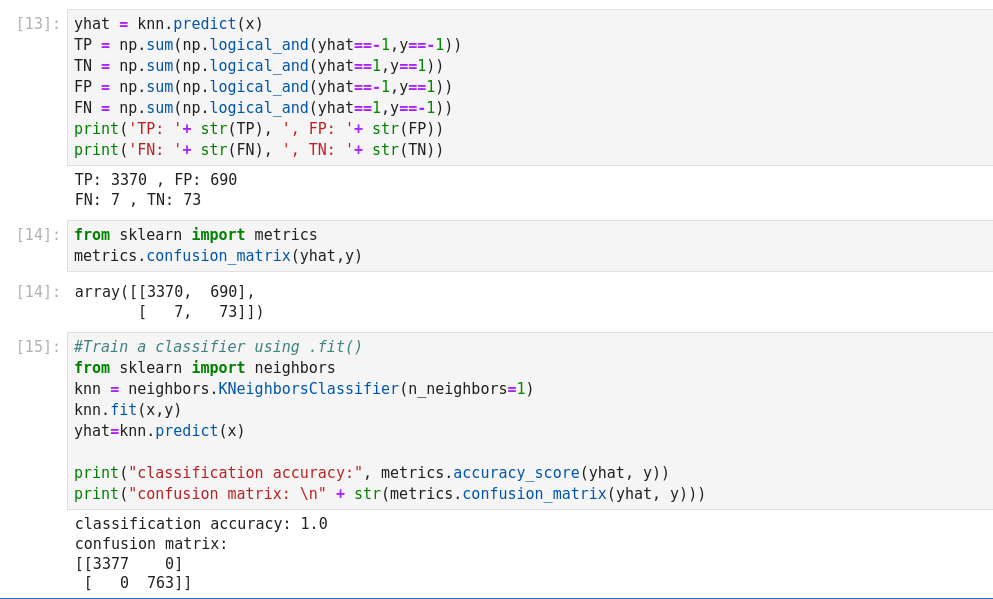
The basic measure of performance of a classifier is its accuracy. This is defined as
the number of correctly predicted examples divided by the total amount of examples.


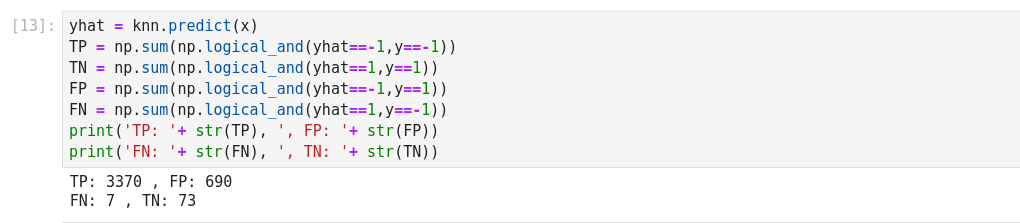
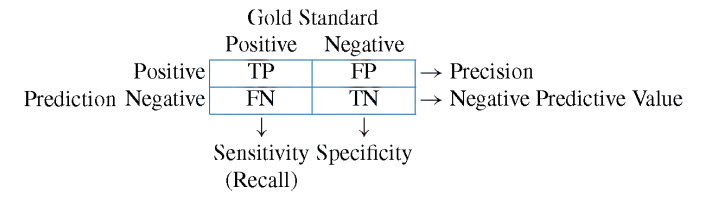
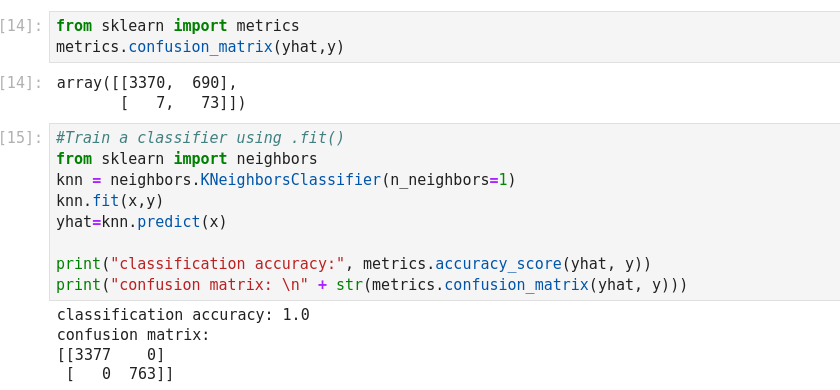

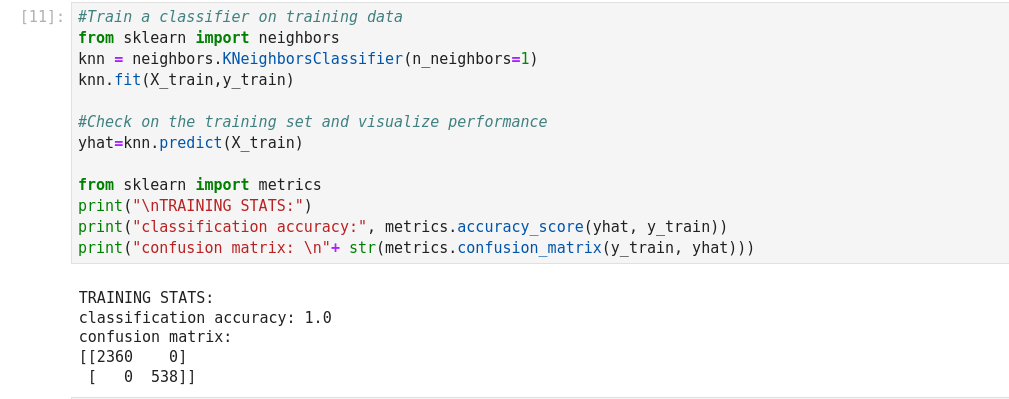
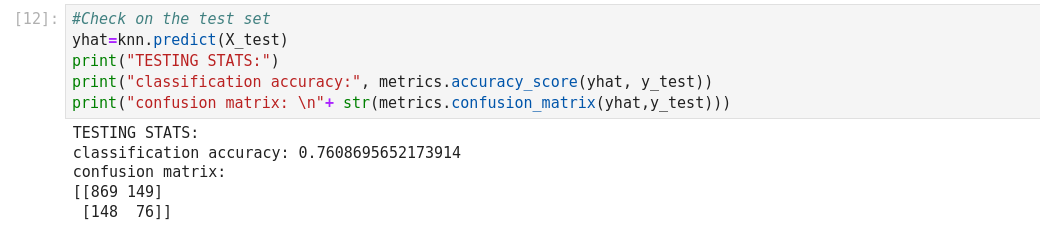
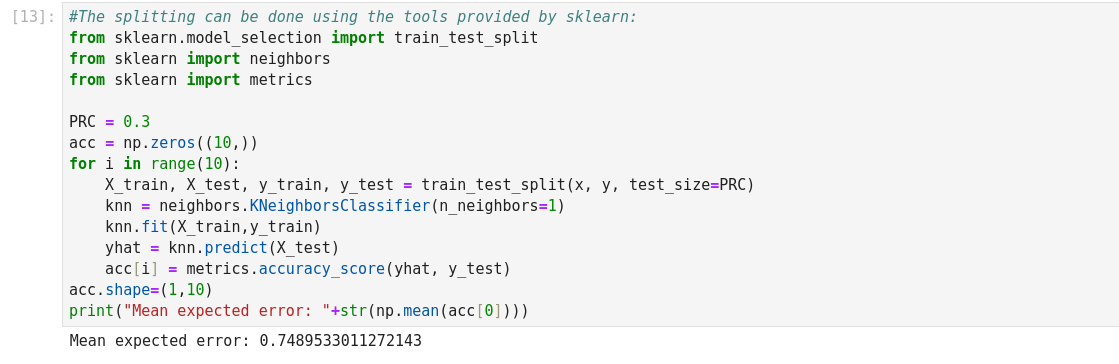
As we can see, the resulting error is below.81%, which was the result of the most
naive decision process. What is wrong with this result? Using the expected error on the test set, we can select the best classifier for
our application. This is called model selection. In this example we cover the most
simplistic setting. Suppose we have a set of different classifiers and want to select
the “best” one. We may use the one that yields the lowest error rate.

(* Nota: la section sur le Machine Learning présente les outils de façon très très théorique, moins utilisée dans le pratique, réf: Kaggle *)
