




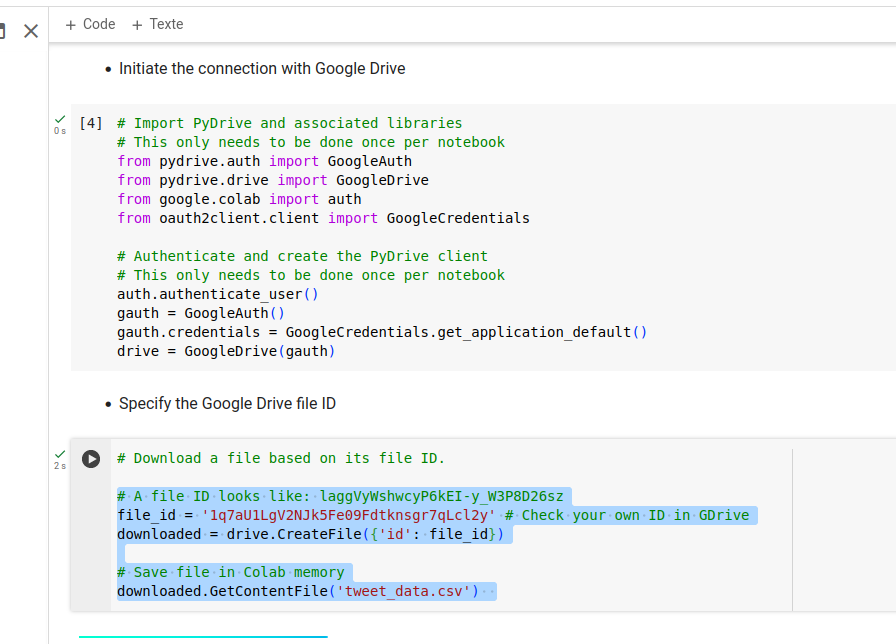
La procédure d’utilisation de Jupyter pour ce tutoriel utilise le compte de Google Drive.
Après avoir installé PyDrive dans Jupyter, dans son propre compte Google Drive, on y place la base de données ‘tweet_data.csv’.
Il a fallu aussi y inséré le # d’Id placé dans le lien du fichier:
# A file ID looks like: laggVyWshwcyP6kEI-y_W3P8D26sz
file_id = '1q7aU1LgV2NJk5Fe09Fdtknsgr7qLcl2y' # Check your own ID in GDrive
downloaded = drive.CreateFile({'id': file_id})
# Save file in Colab memory
downloaded.GetContentFile('tweet_data.csv')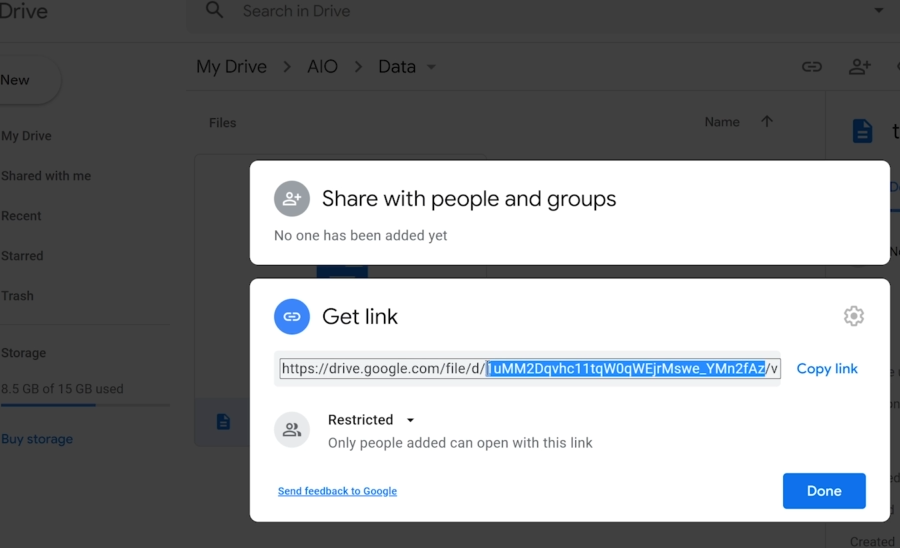







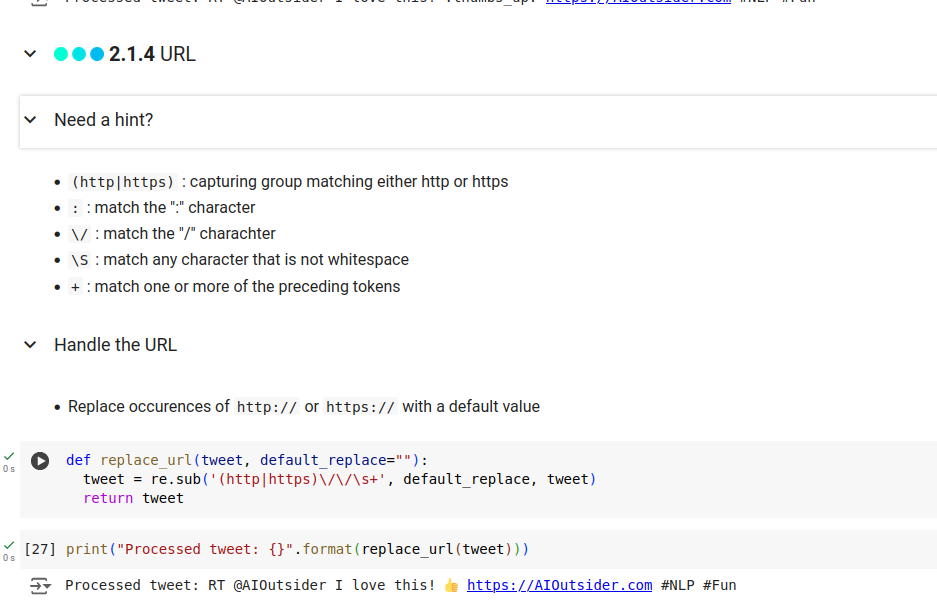
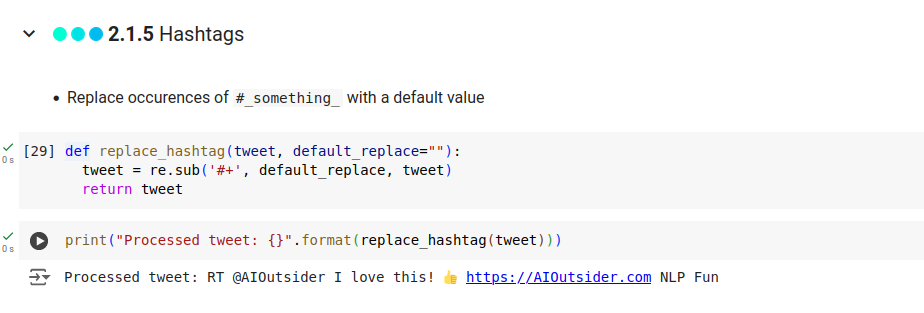
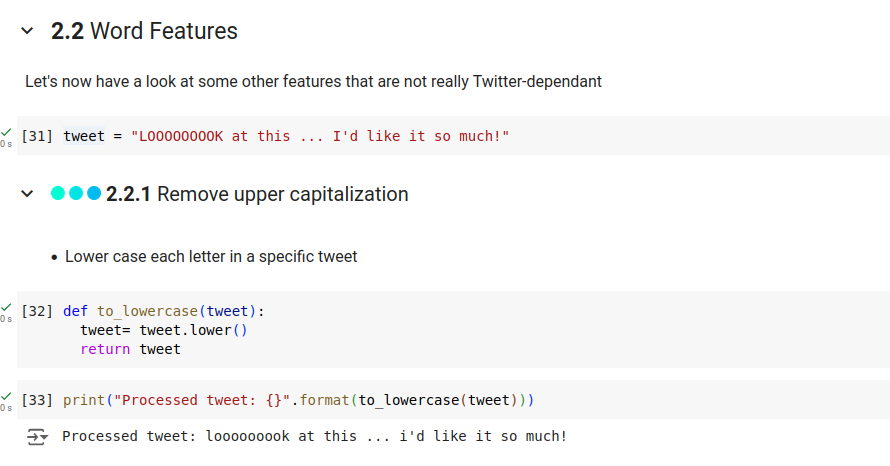



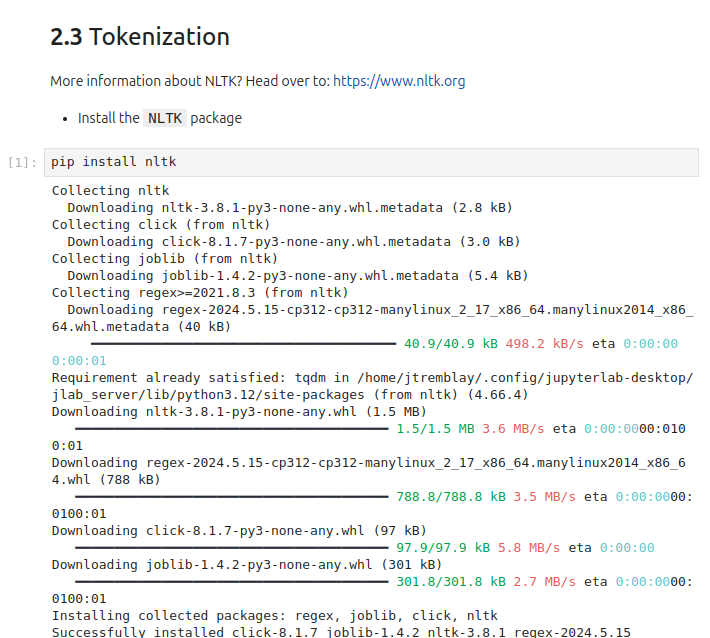
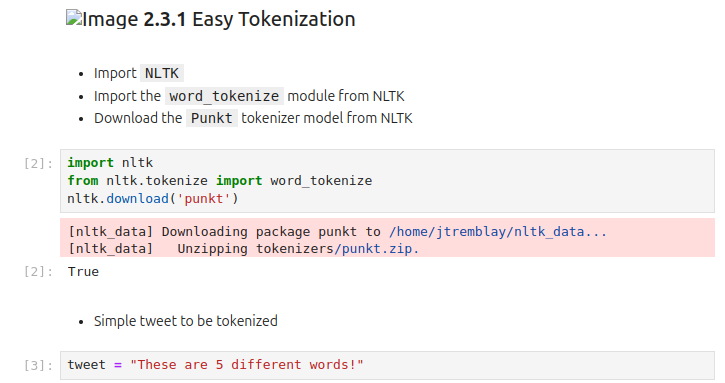
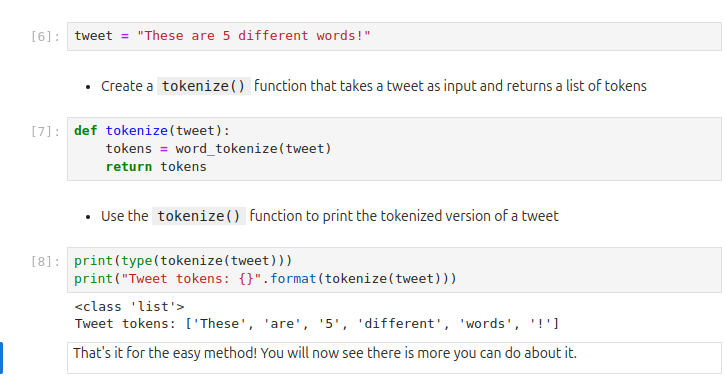
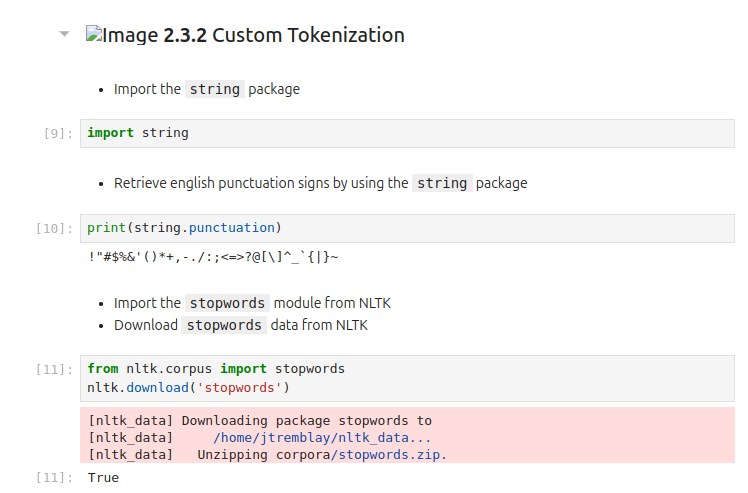
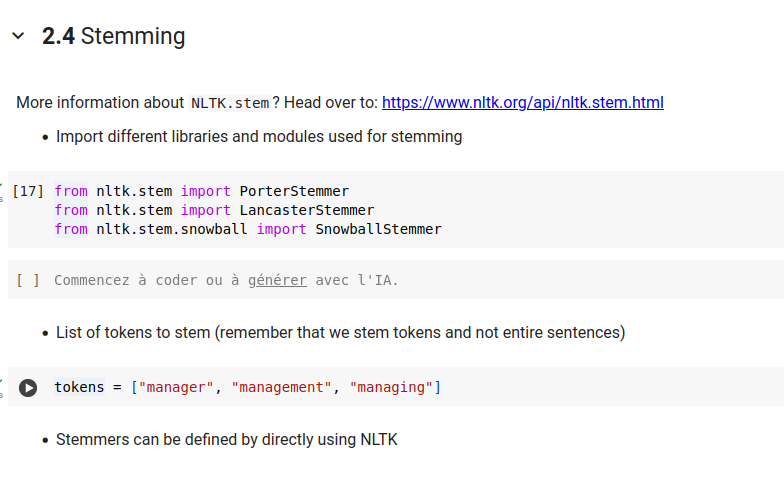
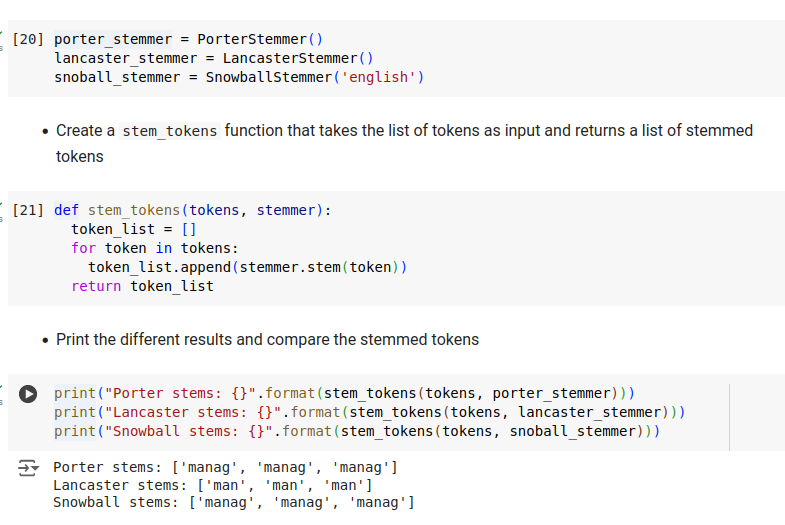


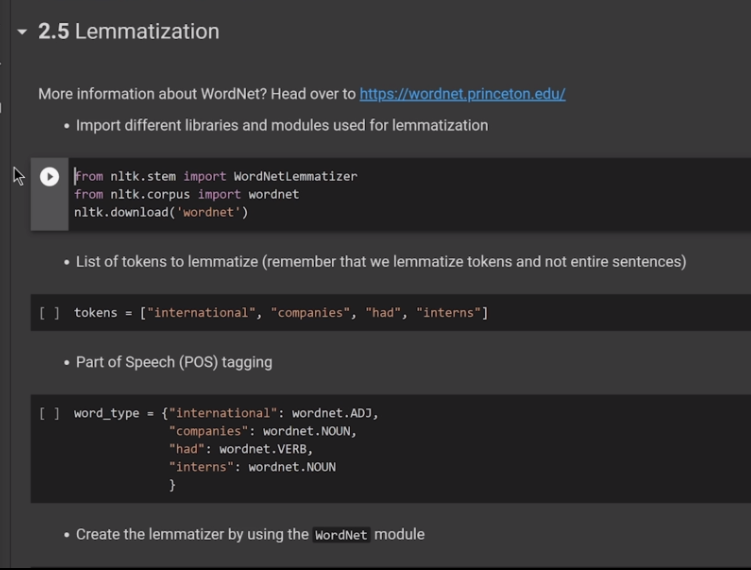
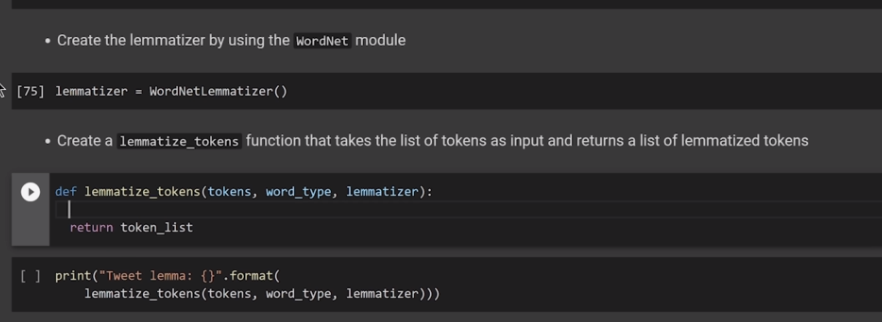






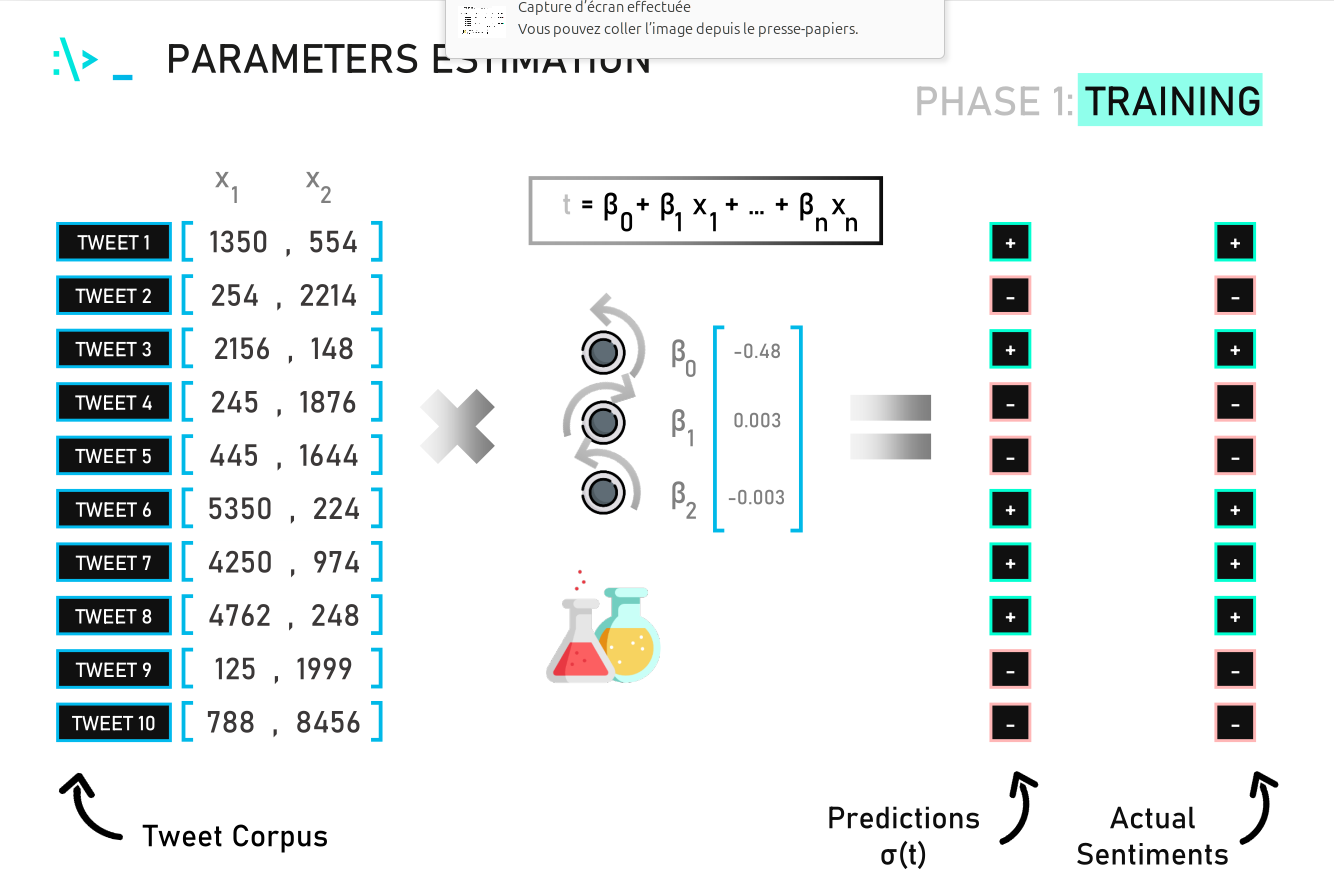
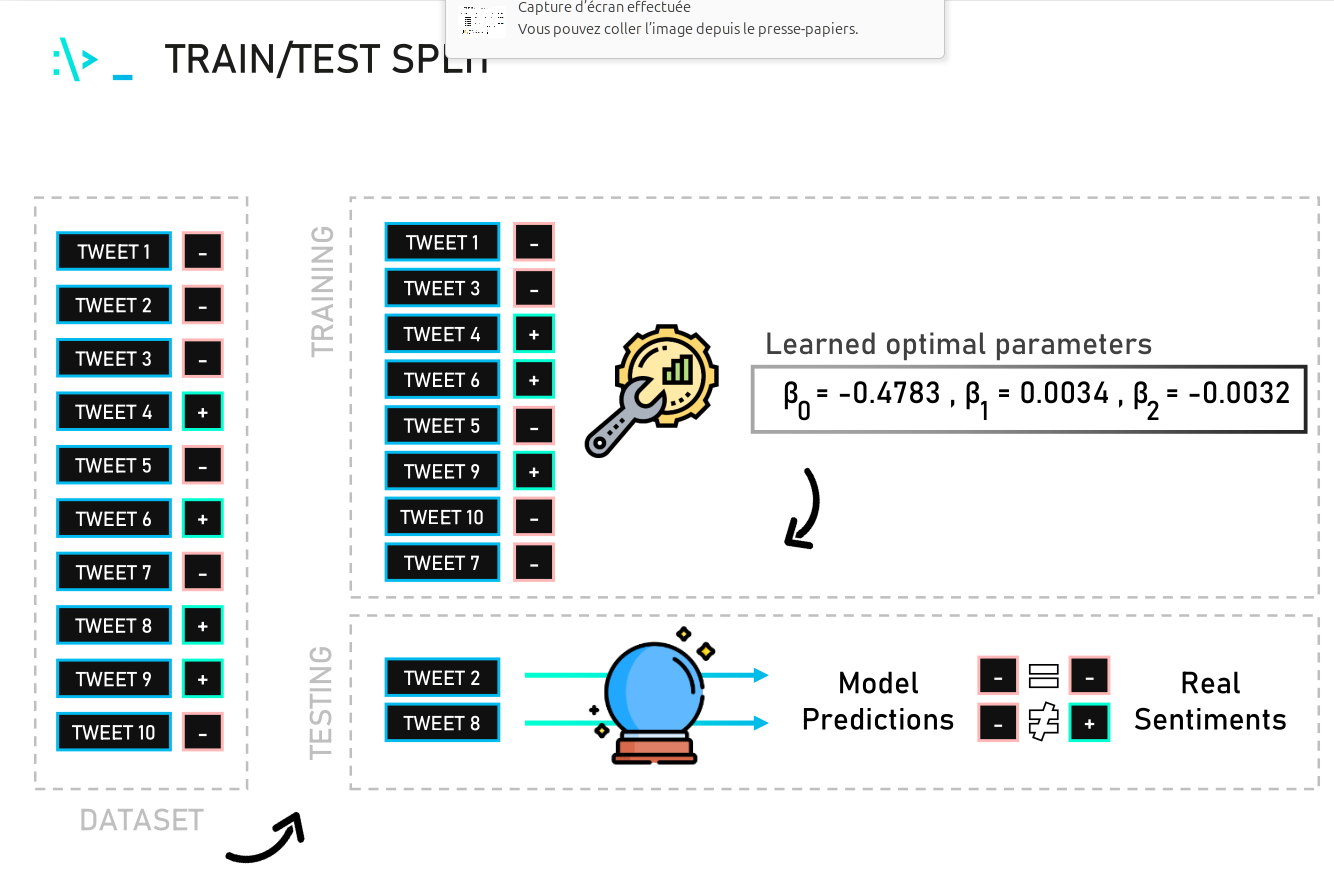
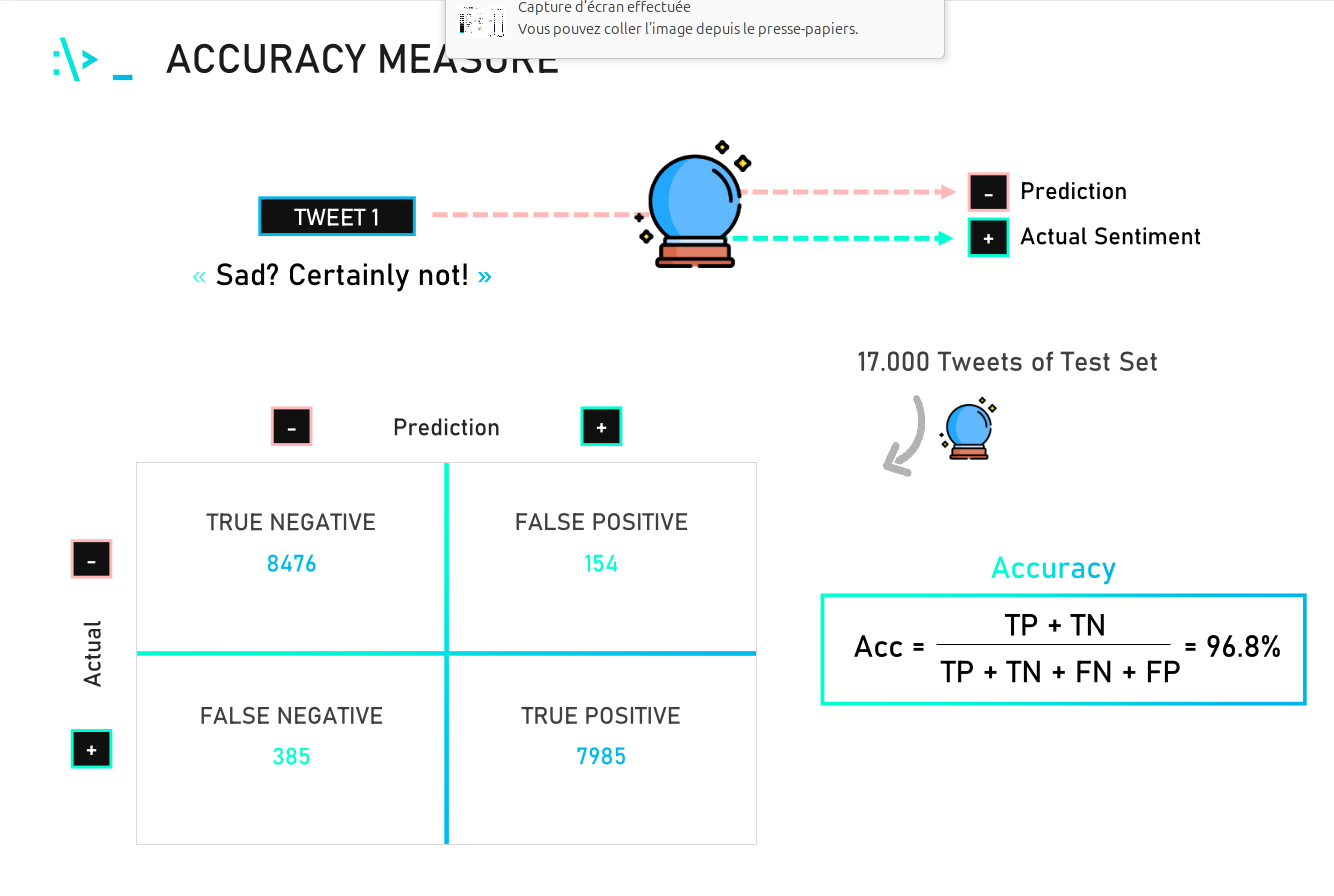

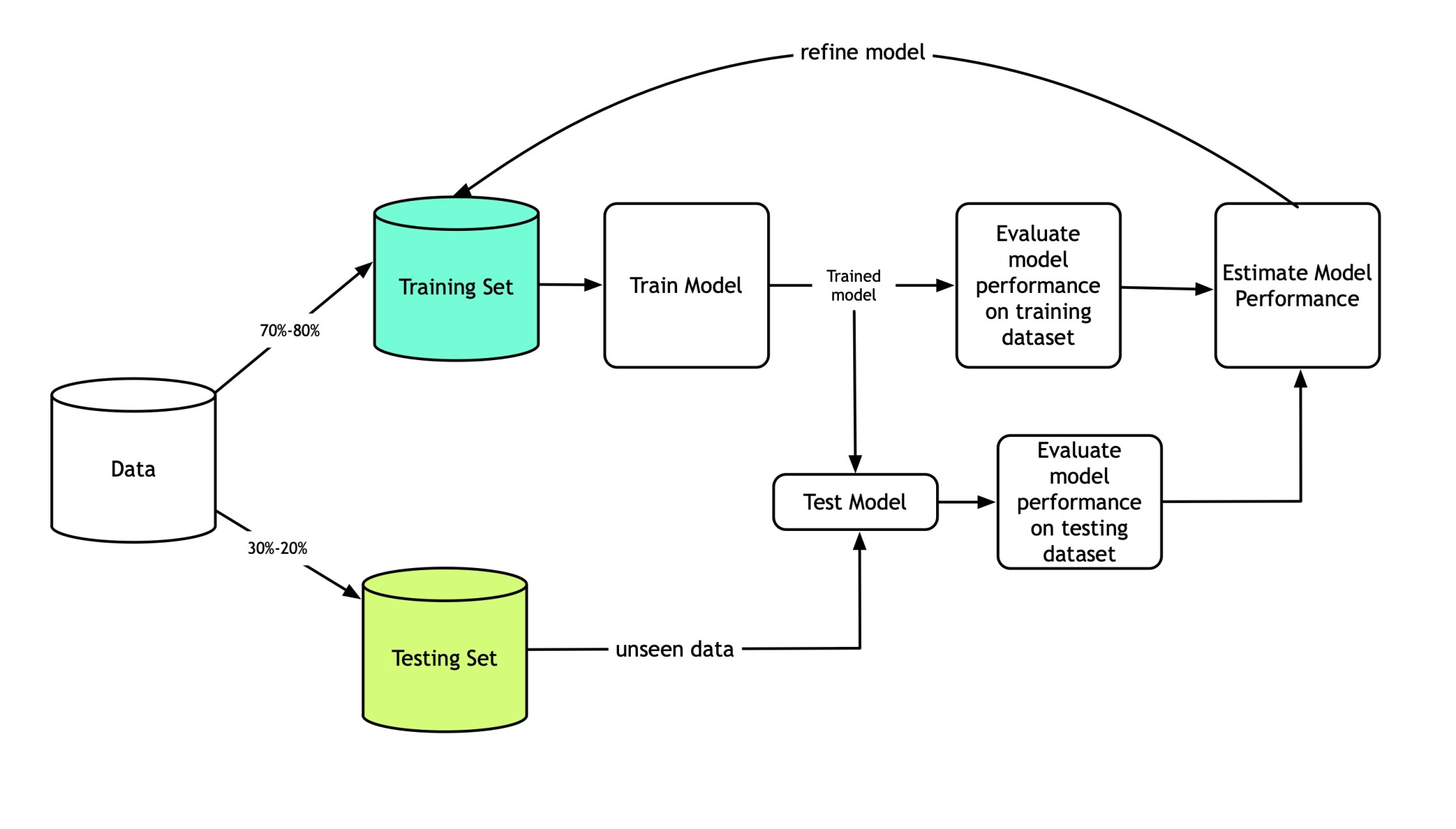
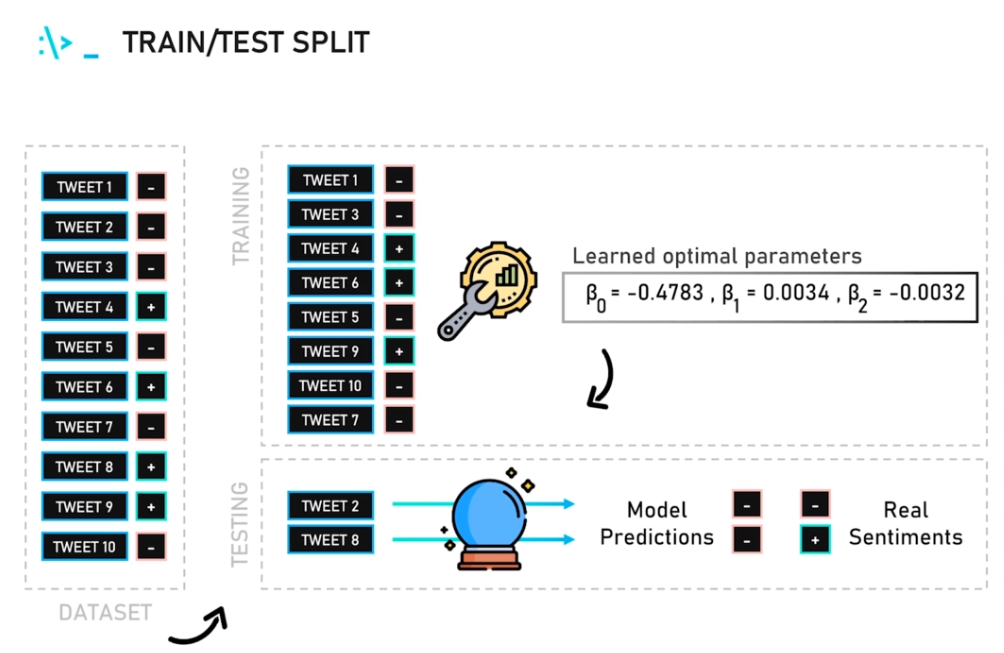
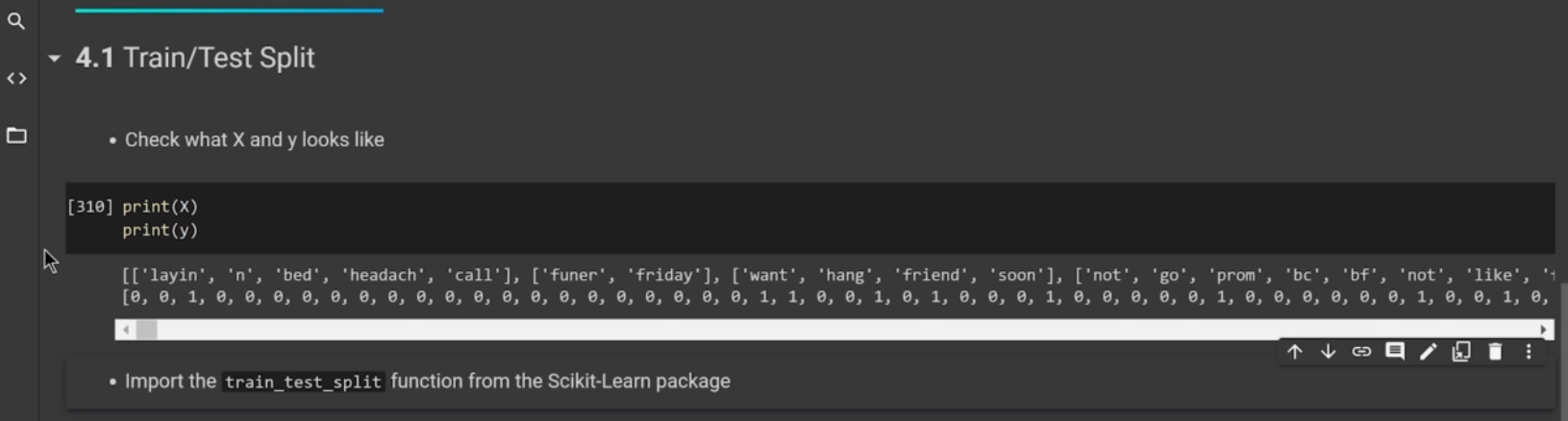

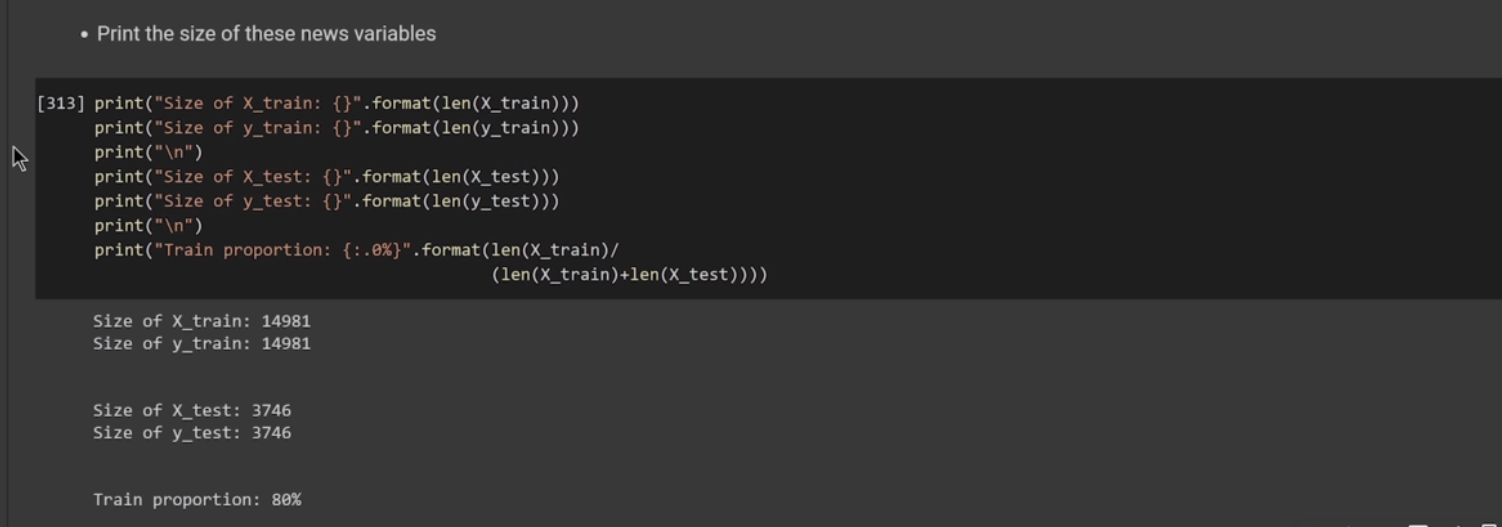
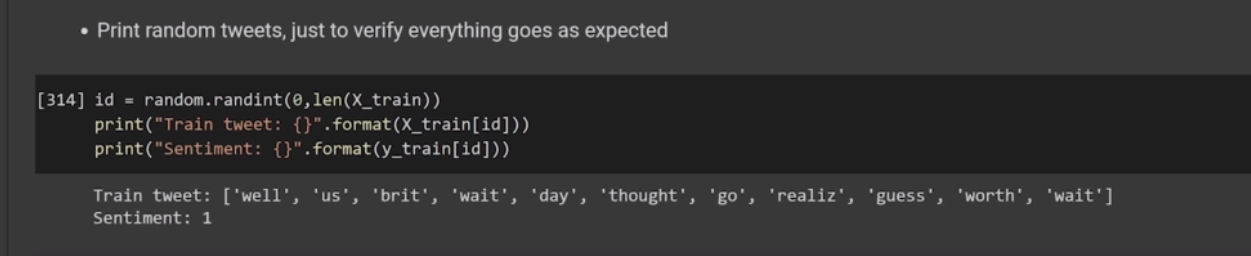
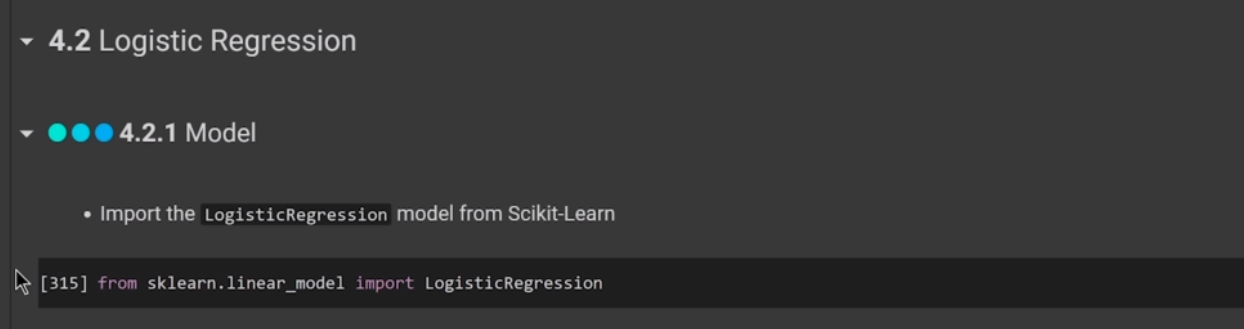

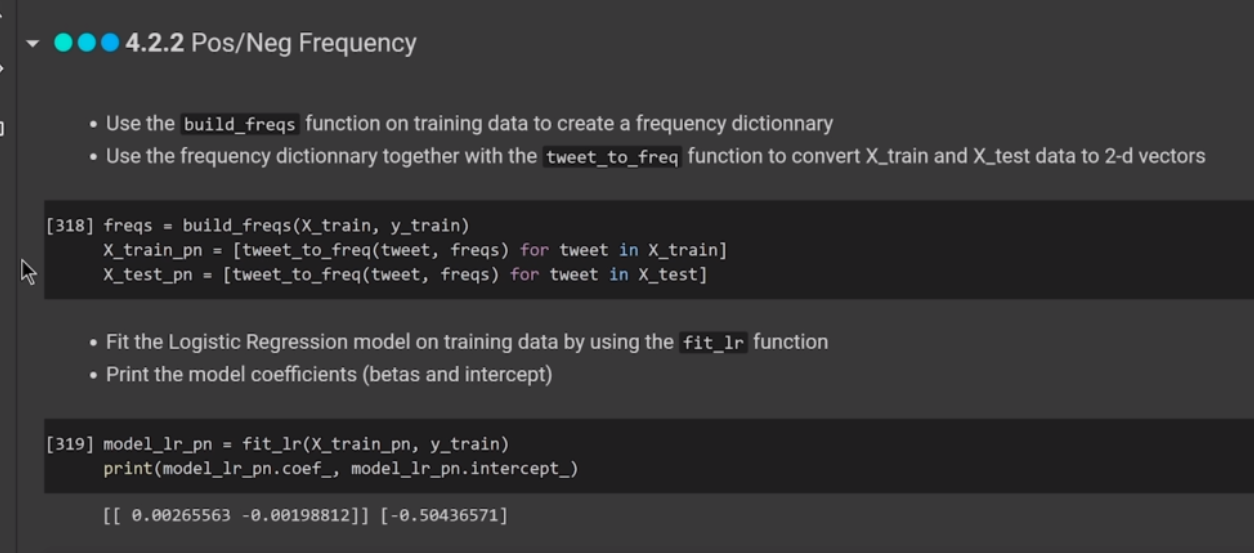

(* 19 juin 2024 *)
